deepseek 使用初印象
2026-05-12
以前抢 coding plan 的时候,我就在调侃,这些服务提供商动不动就不可用,各种限流,429 报错,然后就这还是需要抢的...等 deepseek 赶紧出来教育市场。
前阵子 deepseek v4 真的出了哈,结果我都没第一时间跟进。因为手头上已经有正在用着 glm 的 pro + codex plus 组合,然后现在这阵的 glm 遇到服务不可用已经少了太多,所以没有太强烈的切换的驱动力。 这么迟才来试一试 deepseek。为了信仰,充值了 10 块钱(笑死)。
题外话,glm 背刺老用户这个点,还是挺不爽的。我从 4.7 时代就开始用着了,老套餐的 pro 用量还是给得非常可以的,200 档而不是像现在 150 (折后 130 这种)。 新套餐据说是严重缩水的,而老套餐已经不让再续费了。如果 deeepseek 性价比更高,套餐到期了就准备切换!
(证明我不是键盘侠)
还是用的我自己写的 agent,对接很顺序,改改配置就接上了,只遇到了一个报错是 "reasoning_content must be passed back to the API"。这是一个行为差异,zai 那边是没有强制要求这个的,也很简单修复掉了。
先验证对接完的功能可用性,我跑了之前的那个画金门大桥的测试,deepseek flash 一次成功,效果上比 glm5 弱了一点,但是比 minimax 体感好,至少是一次就出来了。
测试 case 是使用的我的 agent repo 里面的 benchmark。 case 基本上是 terminal benchmark 中挑选的,以及自己加的一些。 关于 benchmark 这种,网上的官方结果都不太可信,只有自己验证出来的信息才更可靠。
基于上我每天会在睡觉前,跑一轮的我的 agent 的 benchmark,第二天早来起来,确认下是否有 regression,让 agent 分析一下 session 找找我的 agent 实现有没有可优化的空间之类的。 这个事情挺浪费 token 的,大概一轮要 4-6 小时才跑完,如果遇到服务不可用导致各种中断,case 的失败率还会上升,所以结果也没有官方那种稳定,有时候第二天早上起来还没跑完的。 反正 coding plan 里面的 token 不用也是浪费,这是一个很好的“浪费” token 的场景。
题外话,如果公司把 token 使用作为拥抱 AI 的指标,这种我是完全不认可的。token 很好烧的,但是关键得看烧出来产生了多少价值。现阶段的 agent,在 demo 阶段很好用,但是在烧 token 到产品转化这一块,离开人的参与是很难实际产出的。
模型用的是 deepseek v4 flash,没有用 pro 是因为我得先试试水看看价格消耗。 跑完测试的 ai 结果对比分析我贴过来:
### 📊 总览
| 指标 | Current (5/8) | New (5/12) | 变化 |
|---|---|---|---|
| **Pass Rate** | 64.86% (24/37) | 62.16% (23/37) | 🔴 **-2.7%** |
| **Functional Pass Rate** | 81.08% (30/37) | 78.38% (29/37) | 🔴 **-2.7%** |
| **Avg Agentic Score** | 92.17 | 88.26 | 🔴 **-3.91** |
### ✅ 进步的任务 (+4)
| 任务 | 旧状态 | 新状态 | Score 变化 |
|---|---|---|---|
| **#6** | ❌ fail | ✅ pass | 52 → **95** (+43) |
| **#7** | ❌ fail | ✅ pass | 55 → **65** (+10) |
| **#14** | ❌ fail | ✅ pass | 60 → **84** (+24) |
| **#26** | ❌ fail | ✅ pass | 100 → 100 |
### 🔴 退步的任务 (-5)
| 任务 | 旧状态 | 新状态 | Score 变化 |
|---|---|---|---|
| **#9** | ✅ pass | ❌ fail | 100 → **5** (-95) ⚠️ |
| **#11** | ✅ pass | ❌ fail | 100 → **60** (-40) |
| **#13** | ✅ pass | ❌ fail | 100 → **60** (-40) |
| **#19** | ✅ pass | ❌ fail | 100 → 100 (functional 掉了) |
| **#24** | ✅ pass | ❌ fail | 100 → 100 (functional 掉了) |
### ⚡ 分数变化(通过状态不变)
| 任务 | Score 变化 | 说明 |
|---|---|---|
| **#10** | 63.3 → 46.7 | ⬇️ 下降 |
| **#12** | 20 → 25 | ⬆️ 小幅上升 |
| **#16** | 60 → 25 | ⬇️ 大幅下降 |
### 📝 结论
**总体略退步**。净变化 -1 个 pass(+4 -5),核心问题是:
1. **#9 暴跌至 5 分**(100→5),这是最严重的回退,需要重点排查
2. **#11、#13** 从满分掉到 60 分,也是显著退步
3. **#19、#24** functional 失败但 agentic_score 仍为 100,可能是非功能性变更
4. 好消息是 **#6 跃升到 95 分**、**#14 跃升到 84 分**,说明某些方面的改进是有效的
大概近 40 个测试 case 中,只比最近的 glm5.1 的结果多出一个失败。
- pass rate 从 64.86% -> 62.16% 降低 2.7%
- Avg Agentic Score 从 92.17 -> 88.26
表现非常惊艳!这比之前测试 minimax 的结果要好太多了,难怪 minimax 股价掉一半。而且这还是 deepseek flash,我有理由相信,如果是 deepseek pro 有可能得出更高的分数。
再看价格这块,这是跑了 4-6 小时的 benchmark 测试集,总共只花了 4.11 块钱,amazing!如果是日常的工作,对 LLM 调用频率不会这么满。所以我们可以把这个当作真正日常工具的 token 消耗的基准参考。 一天4块钱,一个月120,比 pro 的 coding plan 还省了!如果把周未排除那价格还要低,妥妥的价格屠夫。
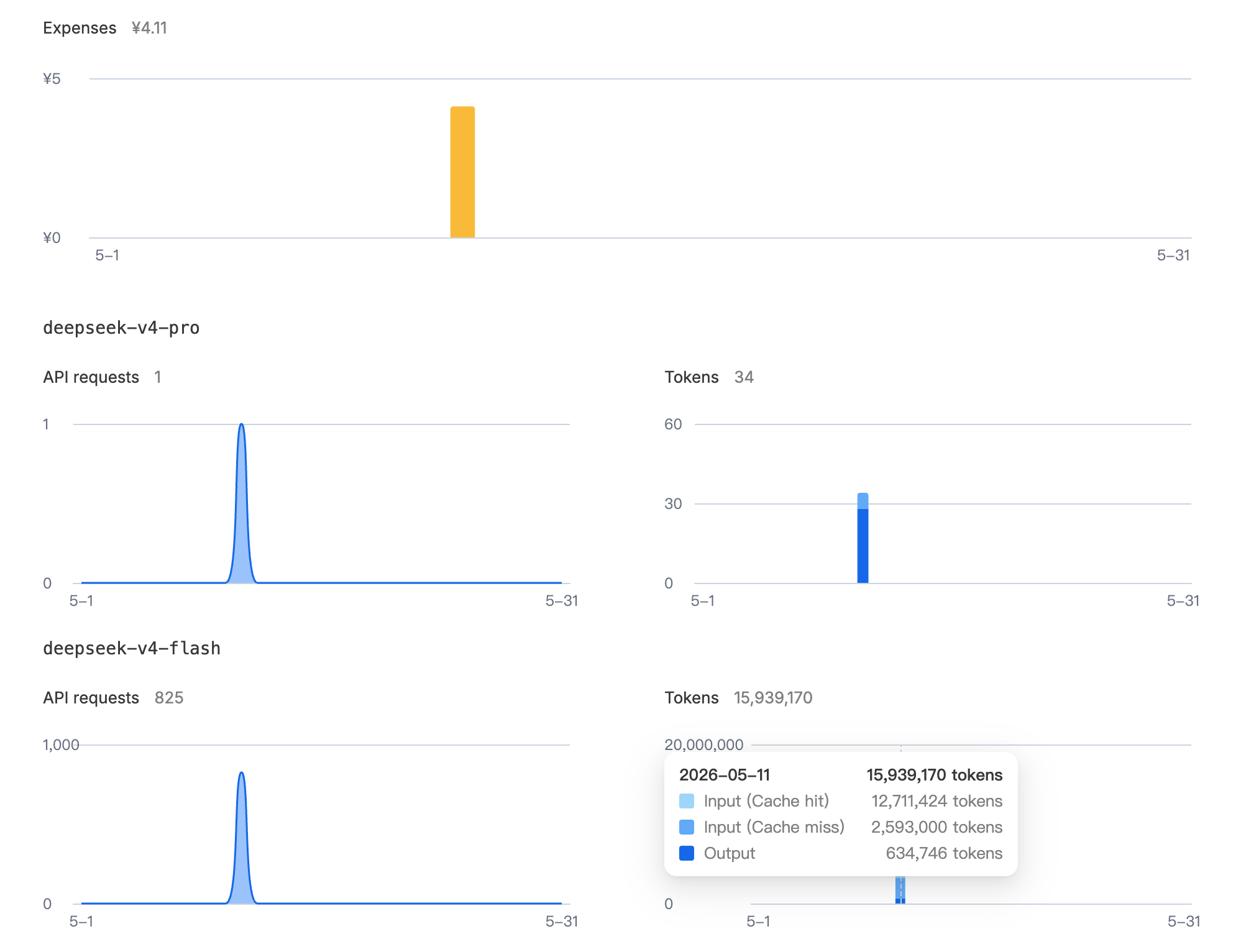
token 数总共是 15,939,170。看看分布,cache hit 大概在 83% 的样子,我没有专门针对我的 agent 优化过缓存命中率,不确定这大概是一个什么样的水平,还有多少价格空间。 主要是 coding plan 那边没有啥太多优化 cache hit 的动力。如果切套餐了,这个还是可以搞一搞。